
Fine-tuning an LLM vs. RAG: What's the Best Choice for Your Corporate Chatbot Build?
Building a corporate chatbot requires going the extra mile to extract the best results. But what is best, fine-tuning an existing LLM or implementing a RAG architecture?


There’s been a lot of discussion in AI circles recently about whether ‘fine-tuning’ or ‘RAG’ (Retrieval Augmented Generation) gives better LLM (Large Language Model) results.
If you’ve been following this newsletter for a while, you’ll know I was writing about RAG before it became commonly known as RAG.
In fact, I originally called it the “Corporate Brain”, for want of a better name, and offered it as a way of eliminating ‘corporate amnesia’—in other words, helping organisations remember their own data and knowledge with access through a corporate chatbot.
We’ll get into what fine-tuning and RAG is shortly, but the conclusion I come to about which “is best?” may surprise you.
This week’s newsletter is all about the pros and cons of using fine-tuning and/or RAG in your next million-dollar generative AI app, including an overview of what each is.
What it’s not, is a guide on how to implement these generative AI design patterns, although I provide plenty of references for those so inclined to learn the implementation details - including a just-released link to Enterprise LLM creator Cohere’s ‘Chat API with Retrieval Augmented Generation (RAG)’.
RAG and fine-tuning are two of the most important concepts in generative AI to understand if you plan to build your own chatbot, whether you’re a coder, executive or anyone in between.
So without further ado, let’s dive in!
In a recent interview with Semaphor, a news and technology outlet, Rohit Prasad, SVP and Head Scientist of Artificial General Intelligence(!) at Amazon, shared insights about an upcoming release of Alexa.
This new release, arriving soon, will be powered by a freshly developed Large Language Model (LLM), Rohit said,
“The model is fairly large. There’s a pre-training stage where it’s a token predictor. That’s a massive model. And then you’re fine tuning it for voice interactions. You’re grounding it with real world APIs so that it does the right thing at the right moment for you. Plus, you’re using the personal context so it knows things like your favorite team, or the weather in your location.”
When you dig into this paragraph, it provides a great overview of many of the different stages of training an LLM and the design patterns, like RAG, that we are discussing here.
So, let’s kick off by understanding what fine-tuning is?
(Custom) fine-tuning
To make a production-ready LLM that is useful, safe and unbiased (as much as possible), there are several different types of training required.
You can envisage the training of an LLM as a pipeline, outlined at a high-level in the diagram below,
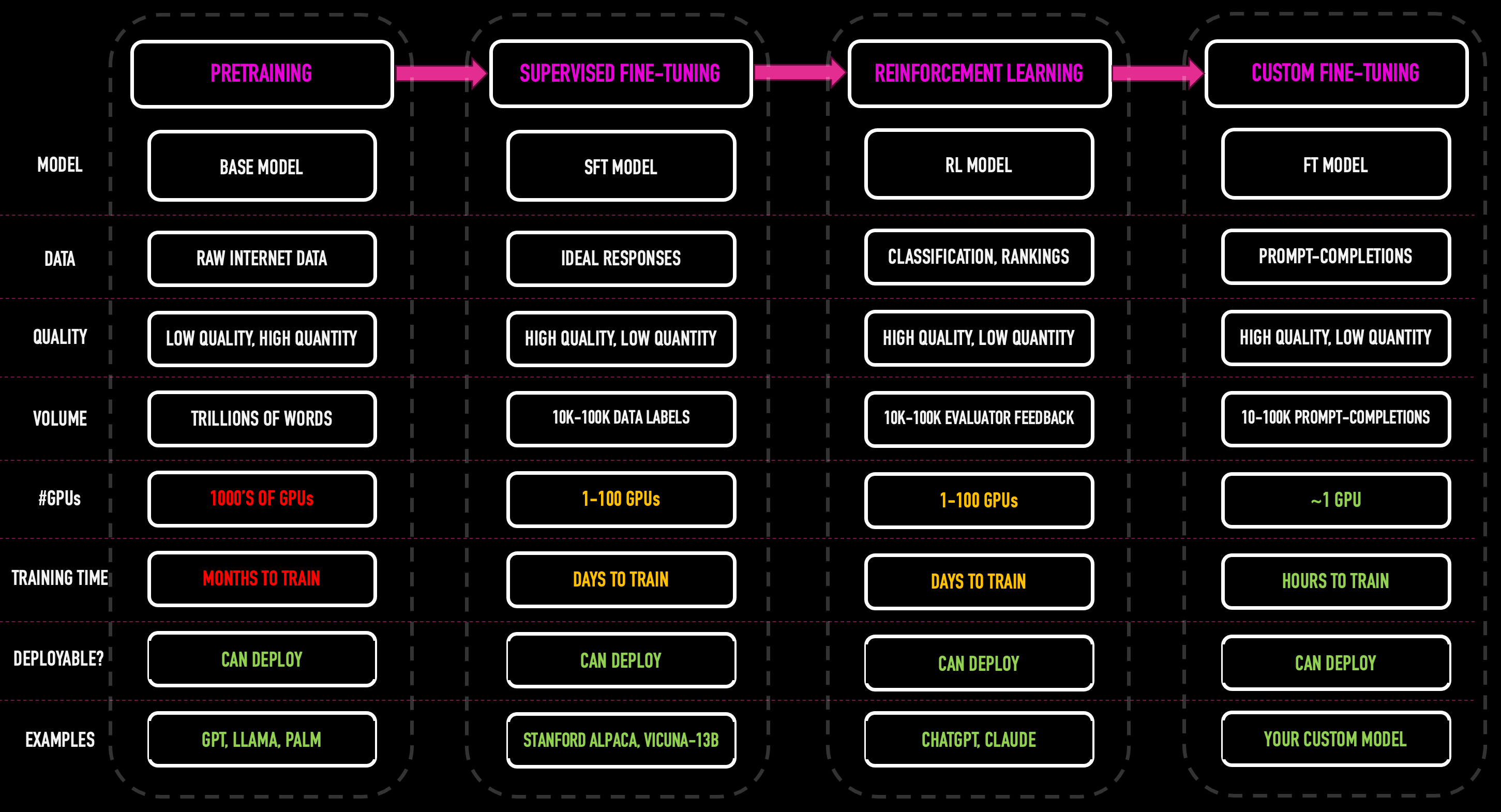
The training pipeline overview
The training pipeline can be broken down into four main stages: Pretraining, Supervised Fine-tuning, Reinforcement Learning and Custom Fine-Tuning.
It’s worth noting that each of these phases has additional complexities and sub-training which I’ve left out of the above diagram for simplicity's sake.
It’s also important to note that fine-tuning itself is used in two places within the training pipeline.
The first is supervised fine-tuning as typically undertaken by the model creators (OpenAI, Meta, etc.) prior to releasing the model to the general public.
The other is what I call custom fine-tuning (also just called fine-tuning, or model fine-tuning) as used by the end developers (you and me) to further tune a model to a specific domain or task.
Although we are only interested in the ‘custom fine-tuning’ training today, it pays to have a general understanding of what comes before that to create the model.
So, let’s quickly dive into this pipeline, which is, at a high level, typical of many LLM creators.
Pretraining
The first step to initialising an LLM’s neural nets is through a process called ‘pretraining’.
I once overheard someone say that “…pretraining is like the university and fine-tuning is like the degree specialisation”—which I think is a pretty good analogy.
Pretraining exposes the model to extremely high quantities of relatively ‘low quality’ data.
The model is fed with terabytes of raw Internet data scraped from websites like Wikipedia, Reddit, Github and others as outlined in the example dataset table below for Meta’s original Llama model.

During this phase, the model learns the relationship between tokens and from that develops basic skills like spelling and grammar so that it can interact with humans in natural language.
There are organisations like CommonCrawl which maintain huge datasets specifically for model pretraining purposes.

This phase is the most resource-intensive and costly process in the entire training pipeline, with pretraining consuming the processing power of thousands of GPUs, each GPU capable of performing billions of calculations per second.
Although costs are coming down, currently, only the very largest and most wealthy global organisations are able to perform pretraining on LLMs of the size of OpenAI’s GPT-4.
It costs millions of dollars (sometimes tens of millions and possibly hundreds of millions) to do a ‘pretraining run’ not to mention the difficulty in securing the evermore scarce physical GPUs.
Outside of OpenAI, Microsoft, Google, Amazon, Meta, Anthropic, Cohere, NVidia of course (who make the most popular GPUs) and a few other well-funded AI and tech companies, the term ‘GPU-poor’ is a common phrase used to describe them.
Supervised fine-tuning (SFT)
During the SFT phase, the LLM creators carry out fine-tuning in a controlled environment, usually with access to the original training data and parameters.
The creators use a labelled dataset, often curated or vetted by experts, to fine-tune the LLM for specific tasks or to improve its performance and safety.
The main goal is to improve the model's general capabilities or to adapt it for broad categories of tasks.
This process is usually well-documented and follows a structured protocol to ensure the integrity and efficacy of the fine-tuning process. It is completed by the model creators.
Reinforcement Learning (RLHF/RLAIF)
During this phase, human annotators through a process typically known as RLHF (Reinforcement Learning with Human Feedback) but also possibly through AI, known as RLAIF (Reinforcement Learning with AI Feedback) provide feedback on model outputs for a range of inputs, often by ranking different responses or providing corrections.
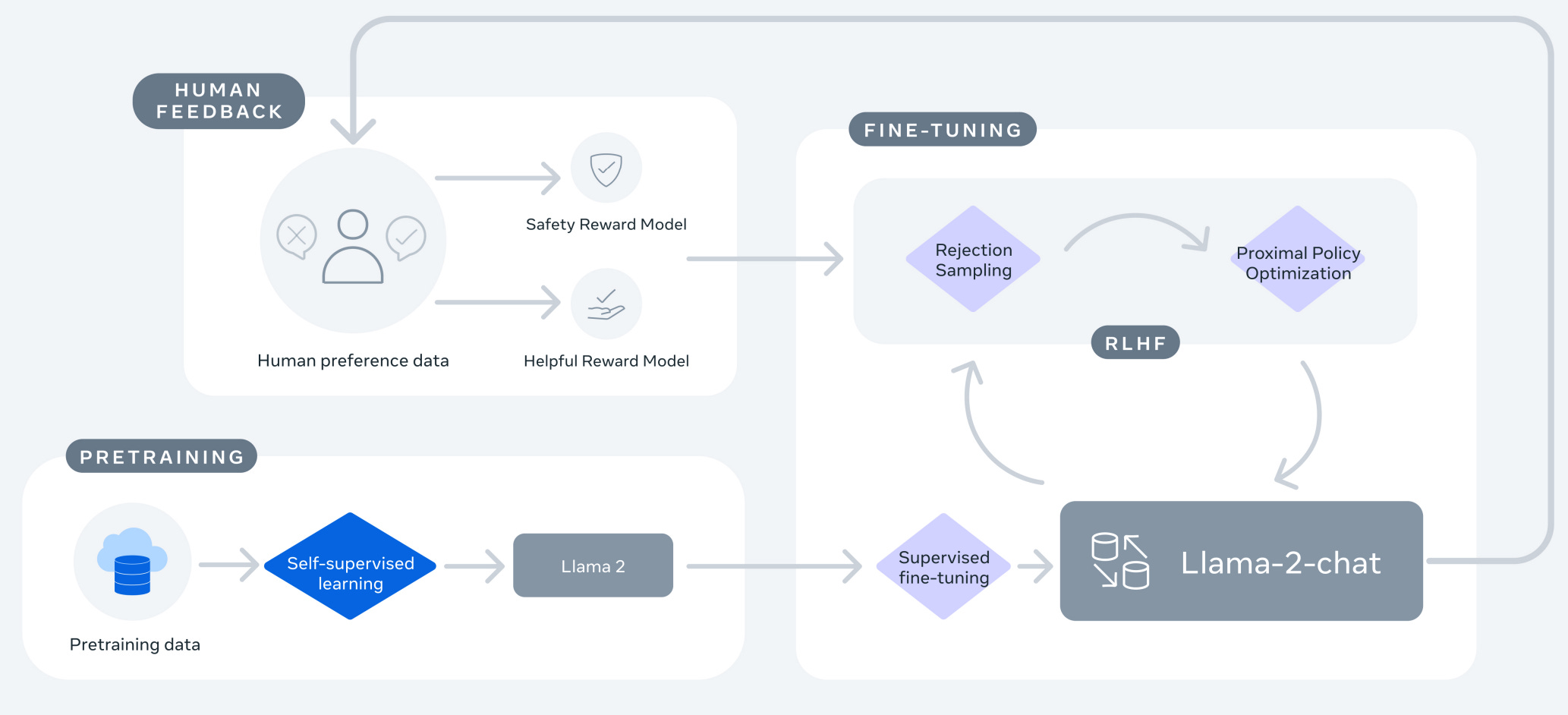
A reward model is trained based on the collected human feedback, which is then used to further fine-tune the model using reinforcement learning algorithms.
This process allows the model to improve its responses based on the feedback, even when the feedback isn't as structured as the labels in a fine-tuning dataset.
